“Mijn testen zijn zo goed als de documentatie”
In het softwaretestproces wordt het gedrag van een systeem bij bepaalde invoer vergeleken met het gewenste gedrag. Verschillen hierin worden als bevinding gerapporteerd: “er is een verschil tussen mijn verwachting en wat het systeem doet”. Sinds de beginjaren van TMap hebben testers zichzelf aangeleerd dat de kwaliteit van hun testen afhankelijk is van de kwaliteit van de documentatie: geen goede documentatie betekent geen goede testen.
We hebben manieren verzonnen om de kwaliteit van documentatie op een hoger peil te krijgen: vroeg in het traject op zoek te gaan naar de juiste documenten, deze reviewen en inspecteren en hier middels formele testspecificatietechnieken op eenduidige en transparantie manieren testgevallen van afleiden. Al deze voorbereiding kost veel tijd, maar “kwaliteit kent geen tijd!” en “de kost gaat voor de baat uit!” Veel van de stappen in het TMap werkproces zijn gebaseerd op het volledig en bruikbaar krijgen van documentatie als ’testbasis’. We hebben zelfs onze testplannen voorzien van ontsnappingsclausules, mocht de documentatie van onvoldoende kwaliteit blijken. En hoewel de eerdere versies van TMap nog testtechnieken beschreven om andere informatiebronnen als testbasis te benutten, zijn deze gaandeweg de tijd komen te vervallen.
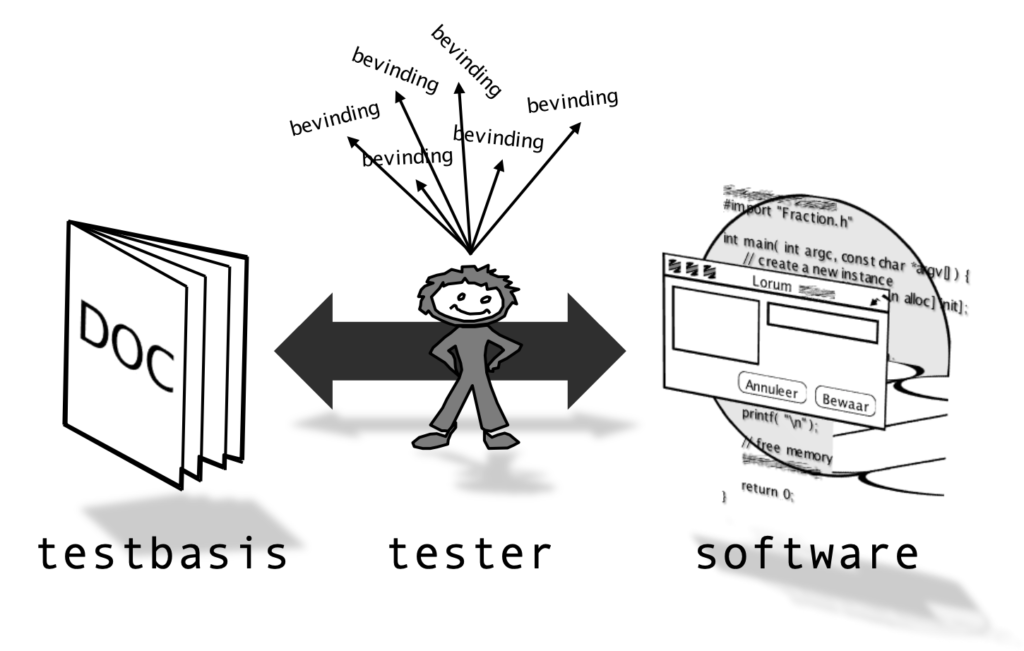
In de praktijk blijf je als tester een ontevreden gevoel aan overhouden aan die totale afhankelijkheid van functioneel ontwerpen, systeembeschrijvingen en requirements. Het komt vaak voor dat bevindingen uit de testuitvoering niet direct een relatie hebben met een stelling in de documentatie en dit leidt regelmatig tot discussie met ontwerpers en ontwikkelaars. Documentatie is echter niet de enige informatiebron die als testbasis kan dienen. Ook het verwachte gebruik van de software, de software zelf en de ervaring van de tester zijn betrouwbaar, eerder beschikbaar en leveren vaak betere resultaten op.
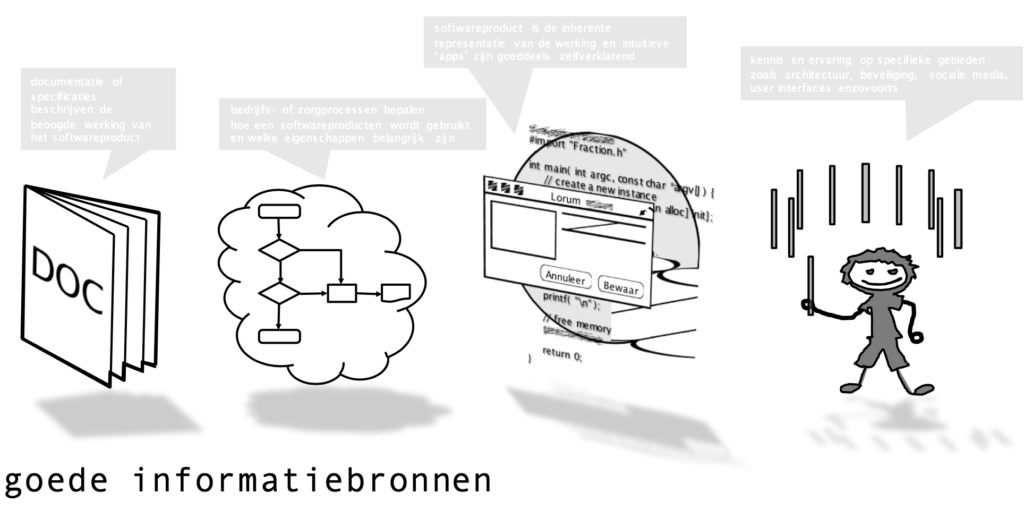
Vier informatiebronnen

Documentatie (hiertoe behoort de specificatie van de software zoals een functioneel ontwerp, maar ook bijvoorbeeld een abstract voorontwerp, een commerciële productbeschrijving, user stories en afspraken uit vergaderverslagen) zijn ideaal om testen op te baseren: je kunt regel voor regel door een document, iedereen kan er over beschikken, je kunt er ‘een klap’ op geven en er bestaan vele testspecificatietechnieken voor. Ook is er niet heel veel voorkennis nodig om als tester gebruik te maken van documentatie: als je kunt lezen kom je over het algemeen een heel eind. Documentatie als model voor de beoogde werking van software kent een lange traditie en testtechnieken als beslistabellen,
Het nadeel van documentatie als testbasis is echter dat de test nooit beter kan worden dan de documentatie en dat het grootste deel van de testtijd gaat zitten in het specificeren van testen. Niet heel motiverend in een agile werkomgeving en funest in een project waar tijdsdruk een rol speelt. Omdat de documentatie ‘de baas’ is over de werkende software is een testtraject dat gebaseerd is op documentatie stuurloos als de documentatie te laat, of niet compleet, wordt opgeleverd.
Documentatie als testbasis relateert aan de ISO 25010 kwaliteitsattributen functionele compleetheid en functionele juistheid.
Het gebruik van de software (hiertoe behoren werkprocessen en inzicht in het werk van de eindgebruiker) is een ander krachtig model voor de beoogde werking software. Als alleen het beoogde gebruik van de software als testbasis wordt gebruikt dat worden er geen overbodige testen uitgevoerd: alle testen zijn direct te relateren aan de verwachte handelingen van een gebruiker. Je kunt zelfs eindgebruikers bij de testen betrekken, bijvoorbeeld om hun handelingen te inventariseren en hiervan testspecificaties op te stellen met een datacombinatietest. Soms zijn formele werkprocessen beschikbaarbaar, die met een procescyclustest tot testgevallen kunnen worden herleid. Ideeën over het gebruik van de software zijn over het algemeen eerder beschikbaar dan ideeën over de werking van de software; software wordt immers gebouwd met een bepaald gebruiksdoel voor ogen.
Een nadeel van het gebruik van de software als testbasis dat er tot in lengte van jaren fouten in de software kunnen blijven zitten in niet-geteste delen van de software. Alle delen die immers niet gebruikt worden zijn ook niet getest. Het stelt ook hogere eisen aan de vaardigheden van de tester: deze zal zich goed moeten kunnen verplaatsen in de taken en doelen van de eindgebruiker. Een ander nadeel is dat bij wijzigende processen het onduidelijk is of de software van voldoende kwaliteit is om dit nieuwe proces te ondersteunen.
De software (hiertoe behoort de ‘voorkant’, met menu’s, knoppen, schermen, maar ook API-documentatie, zowel als de ‘achterkant’, met databasestructuren, configuratiebestanden en broncode in versiebeheersystemen) is een dankbare bron van ‘beoogde werking’. Menu’s van software zijn voorzien van opties met namen die functionaliteit suggeren: ‘print’, ‘boek factuur in’, ’toon details’, ‘zet klok’. Databases hebben een opbouw die (middels de CRUD techniek) voorzien moeten zijn van bijbehorende ‘maak’, ‘wijzig’, ’toon’ en ‘verwijder’ functionaliteit. De API-documentatie (Swagger) verklaart de beschikbare aanroepen. Broncode (en dan voornamelijk de commentaren die bij nieuwe en gewijzigde versies zijn opgenomen) helpen in het zoeken naar verborgen functies.
Testen gebaseerd op de software hebben de neiging om bijna volledig uit testuitvoering te bestaan. Dat kan evengoed een groot voordeel zijn (in agile teams is de beschikbare testvoorbereidingstijd over het algemeen klein) als een nadeel: zonder gedocumenteerde testspecificaties zijn testen slecht herhaalbaar.
Het nadeel van het gebruik van de software zelf als testbasis is dat testen slecht herhaalbaar zijn als er geen testspecificaties zijn opgesteld. Ook is er weinig tot geen aansluiting met het ‘feitelijk gebruik’ van de software zoals dat bij documentatie of processen het geval zou zijn (hoewel dat bij documentatie ook niet altijd het geval hoeft te zijn). De kwaliteit van de testen is nogal afhankelijk van de onderzoeksvaardigheden van de tester, die evenwel met ervaring snel op een hoger peil komen te staan. Ook is de planbaarheid van dit soort testen lastig en werkt het gebruik van software als testbasis vooral goed in moderne scrum-achtige projecten waar testers meewerken in de estimation van user stories.

Ervaring van de tester met vorige versies van het systeem, andere systemen, ideeën over gebruikersinterfaces en softwareontwikkeling en kwaliteit van software in het bijzonder kan een uitstekende bron zijn voor het testen van software. ‘Gevoel’ en ‘intuïtie’ kunnen hier een grote rol spelen, die worden gevoed door de ervaring die eerder met deze software, of soortgelijke (delen van) software is opgedaan. De ’testprofessional’ onderscheid zich hier van de incidentele tester. De unieke inbreng van de tester kan snel testresultaten opleveren, zowel bij statische als dynamische testen. De testen zijn goed voor te bereiden en het is mogelijk voor bepaalde testen specialisten in te huren (pentest, performancetest, usabilitytest).
Met ervaring komen ook nadelen. De testkwaliteit is volledig afhankelijk van de tester en ervaringsdeskundigheid is buiten het team moeilijk te vinden. Ook kan ingevlogen ervaring te specifiek of niet voldoende passend zijn, waar je pas in een later stadium achter komt (‘hoezo kun je alleen pentesten op een webapplicatie doen?’).
Voor- en nadelen van iedere testbasis
Iedere testbasis kent voor- en nadelen. Documentatie is vaak niet volledig en meestal niet tijdig beschikbaar. Alleen testen hoe de software wordt gebruikt laat veel fouten onverlet. Kijken naar de werking van de software levert geen inzicht in functies die er hadden moeten zijn. En de ervaring van de tester kan onvoldoende zijn. De truuk is, om bewust te zijn van de eigenschappen van elk van de informatiebronnen.
(tabel voor- en nadelen)
Volgorde in de toepassing
Niet iedere informatiebron is op hetzelfde ogenblik beschikbaar: informatie over het beoogde gebruik is bijvoorbeeld eerder beschikbaar dan de software zelf.
Relatie met ISO kwaliteitsattributen
ISO kwaliteitsstandaarden 25010, 25012 en 12207 beschrijven 42 kwaliteitsattributen die het totaal van eigenschappen van software omvatten, plus een gedegen opsomming van informatiebronnen die gebruikt moeten worden om de mate waarin voldaan wordt aan de kwaliteitseigenschap te bepalen. ISO 25010 heeft kenmerken die van documentatie kunnen worden afgeleid. Andere kenmerken, zoals gebruikseffectiviteit, hebben meer relatie met het gebruik van software. Portabiliteit en stabiliteit hebben te maken met de software zelf. Gebruiksvriendelijkheid en leerbaarheid haal je uit observaties en ervaring. Met onze vier informatiebronnen is een eenduidige brug vanuit de testbasis naar de kwaliteitsattributen ontstaan, die waar nodig gebruikt kan worden om te verdiepen, te formaliseren of juist te verlichten.
(tabel relatie testbasis met ISO kwaliteitsattributen)
Klavertje vier, of FEW HICCUPPS
In 2012 beschreef Michael Bolton een lijst van informatiebronnen die hij gebruikte als testbasis: history, image, comparable products, claims, users’ desires, product, purpose en statutes. Verschillende van deze informatiebronnen overlappen elkaar (purpose, claims en users’ desires bijvoorbeeld) en de lijst was niet volledig, getuige de latere toevoeging van explainability en world, en een random ‘F’. Waar de lijst de plank echter misslaat, is het negeren van de ISO kwaliteitsstandaarden: de lijst probeert een mate van volledigheid te bereiken die het niet behaalt. Gebruik van het klavertje vier geeft, naast een betere invulling van de testbasis, de mogelijkheid om naadloos aansluiting te vinden bij de internationele ISO kwaliteitsstandaarden.
 De pyramide van Martin Fowler, auteur van het boek
De pyramide van Martin Fowler, auteur van het boek